
Before we start to learn how to do Web Scraping, we need to understand what web scraping is. In simple terms, it’s a process of scraping data from a website.
Imagine you want to get the rating of 100 movies from Rotten tomatoes.com, if you try to do this manually it would take a long time. You would end up typing the name of each and every movie in google. Sounds boring right? What if I say you can let your PC do this and chill while it does the job in a matter of minutes.
Checklist for Web Scraping
The difficulty of Web Scraping is dependent on your requirement and the website itself. You can scrape data from most of the websites without any issues, but you might come across some websites that might have mechanisms that might prevent you from scraping data. But don’t worry, we are not going to speak about the advanced things yet, so let’s stick with the easy stuff for now.
- What data do you want? – Before we start the scrapping, we need to understand what data we want and only focus on that
- Where to scrape? – Once you are clear about what you want to scrape, the next step is to find where we can get it from. Take the example of getting a rotten tomatoes rating for 100 movies. Here the rotten tomatoes rating is the data you want and if you do some research you can find that the data is available in multiple sources and as per your requirement you need to decide and go with the best option.
- How to scrape – There are many libraries for web scraping such as Scrapy, Beautiful Soup, Selenium etc. You can check their documentation if you want to try out these libraries. For this article, we are going to use Selenium.
Web Scraping with Selenium in Python
Now that you know about the Theoretical side of web scraping, let’s move on to the technical side of it. I will be using python as my programming language and Selenium as the web scraping library.
Setting up the project
- Create a python project and set up a virtual environment
- Install the Selenium Module (pip install selenium)
- Install Chrome Drivers
Selenium requires a driver to communicate with the browser. Without the driver, selenium won’t be able to interact with the browser, so it’s really important to download that and initiate it first before we take the other steps.
You can download the latest version of the driver from the below-given link
https://sites.google.com/a/chromium.org/chromedriver/downloads
Once It’s downloaded, make sure to put it inside your project folder
Let’s Start Coding
Project Overview – We will be building a very simple Web Scraper Application which scrapes rotten tomatoes rating of a specific movie from Google.
Step 1 – Import the relevant Classes from Selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import OptionsStep 2 – Before we start the scrapping process, we need to specify the chrome driver’s installation path
options = Options()
PATH = "driverchromedriver.exe"
driver = webdriver.Chrome(options=options, executable_path=PATH)Step 3 – Web Scraping is basically automation, which means we automate a certain behavior of us. Imagine if I ask you to get the rotten tomatoes rating of a specific movie, how would you do it?
- You will open your browser
- You will go to google.com
- You will find the search field and type the name of the movie
- And then from the page that you get as a result you will check the rotten tomatoes rating
Now we are going to do the exact thing as above but instead of doing it manually we are going to automate it
Opening your browser
driver = webdriver.Chrome(options=options, executable_path=PATH)Going to google.com
driver.get("https://www.google.com/")Typing in the name of the movie
Before we enter the name of the movie we should find the input field first. Finding that is simple go to google.com and right click and click the inspect option or you can also press “CNTRL + SHIFT + I“
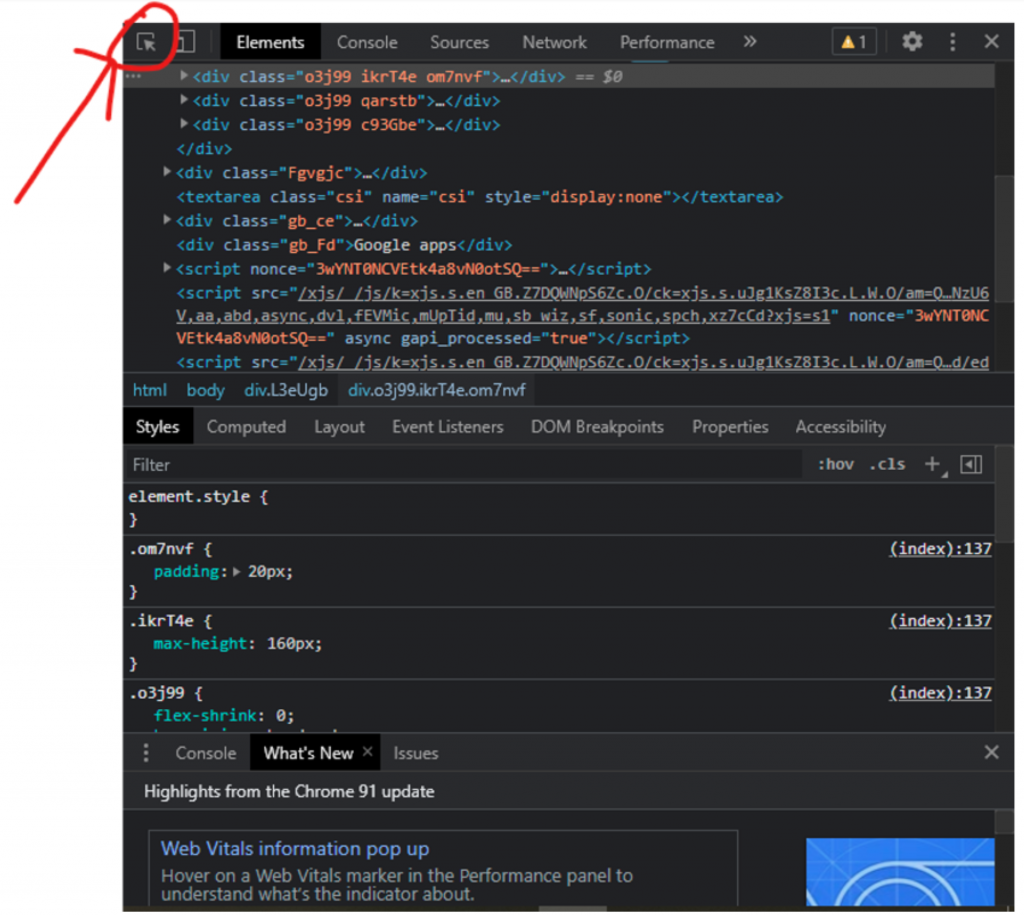
Once the inspector menu is opened, click the highlighted button as shown in the above image. Next, once you click on any element from the web page, this will direct you to the respective element tag.
Once we have found the element, we can select it in many ways such as by class name, tag name, X path, ID, CSS selector, link text, etc. You can use any of the above-mentioned ways, but I would suggest you select it by X Path as this will return the exact location of the element. After that, right-click on the element tag and go to copy and copy XPath.
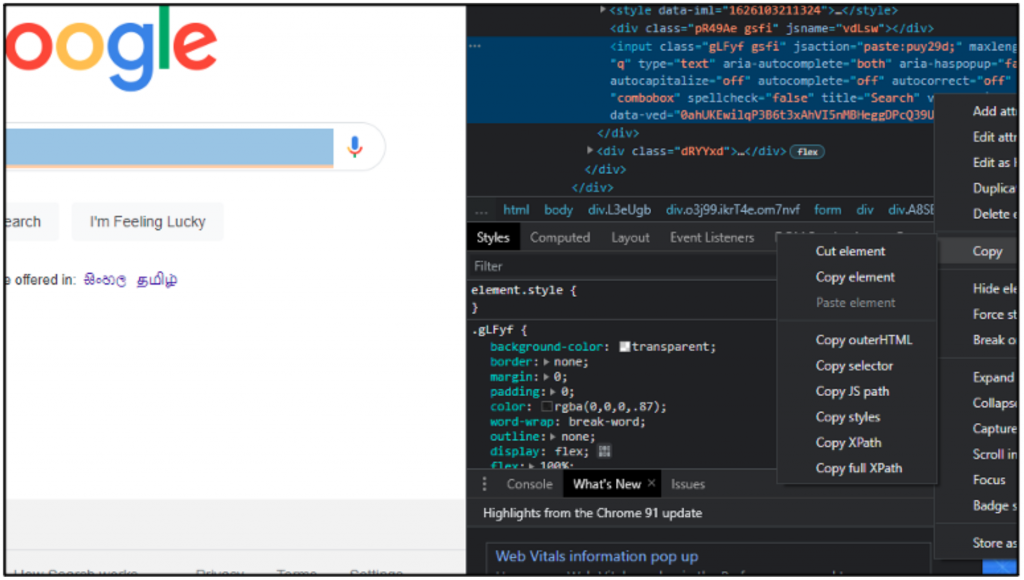
search_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input'))
)Once you have found the input field, the next step is to type the movie name. You can type the movie name by using a method called send_key()
search_input.send_keys(movieName)After typing the movie name we have to press enter, you can do this by calling the below-given code.
search_input.send_keys(Keys.ENTER)Collecting the rotten tomato rating
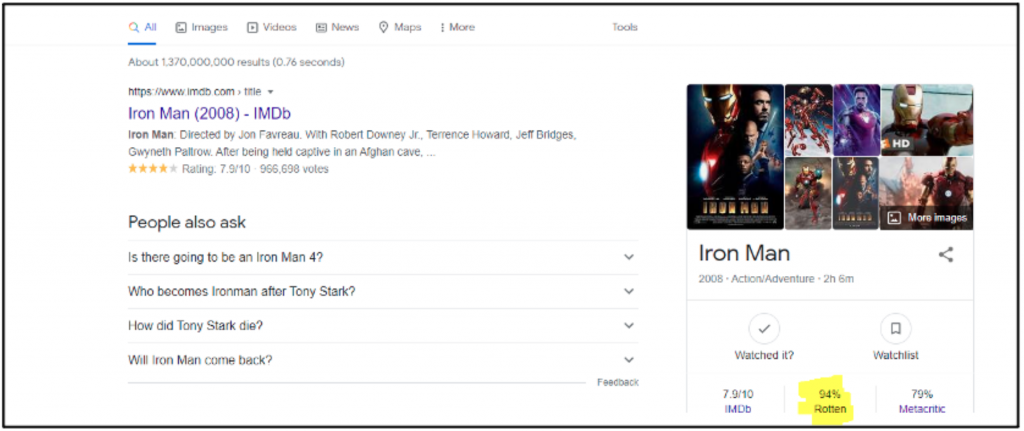
Our final step is to extract the value that is in the above-shown highlighted area. As usual, you have to select that specific element first, after that from that element we have to extract the text. You can do that by simply calling a property called text and this will return the text.
Check = driver.find_element_by_xpath('//*[@id="kp-wp-tab-overview"]/div[1]/div/div/div[2]/div/div[1]/div[1]/a[2]/span[1]')
rating_value= Check.text
print("Rotten Tomatoes Score is " + ""+ rating_value)Conclusion
It’s a simple process, and it won’t even take that much time to get your hands on web scraping. You can check out Selenium documentation to learn more about its functions. I have also attached the full code below, you can check it out.
Full Code
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
def scraping(movieName):
options = Options()
#options.headless = True
PATH = "driverchromedriver.exe"
driver = webdriver.Chrome(options=options, executable_path=PATH)
driver.get("https://www.google.com/")
try:
search_input = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input')) )
search_input.send_keys(movieName)
search_input.send_keys(Keys.ENTER)
Check = driver.find_element_by_xpath('//*[@id="kp-wp-tab-overview"]/div[1]/div/div/div[2]/div/div[1]/div[1]/a[2]/span[1]')
rating_value= Check.text
print("Rotten Tomatoes Score is " + ""+ rating_value)
success = ("success")
return success
finally:
driver.quit()
if __name__ == '__main__':
scraping('run')
Thankyou for your simple explanation! It was really helpful.